一个轻量级的Python实验管理框架,提供:
🚀 批量调度 - TOML 配置文件一键启动多组实验,支持优先级和并发控制
📊 指标记录 - 动态 CSV 管理,upd_row() + save_row() 数据库风格操作
🌐 可视化监控 - 配备 Web UI,实时查看实验状态和日志
📱 飞书同步 - 训练指标实时同步到多维表格,团队协作更便捷
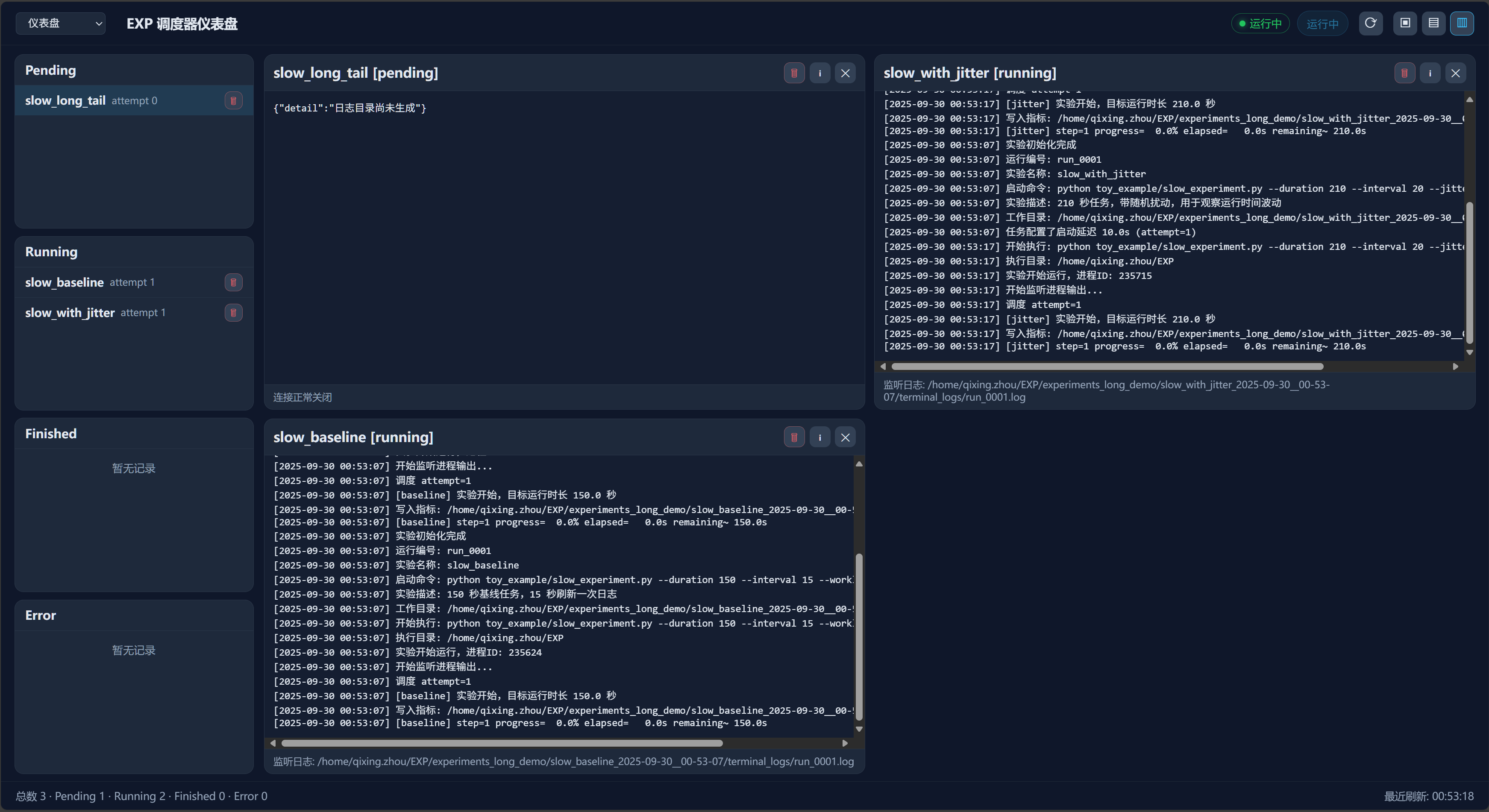
实验管理界面 - 批量调度与实时监控
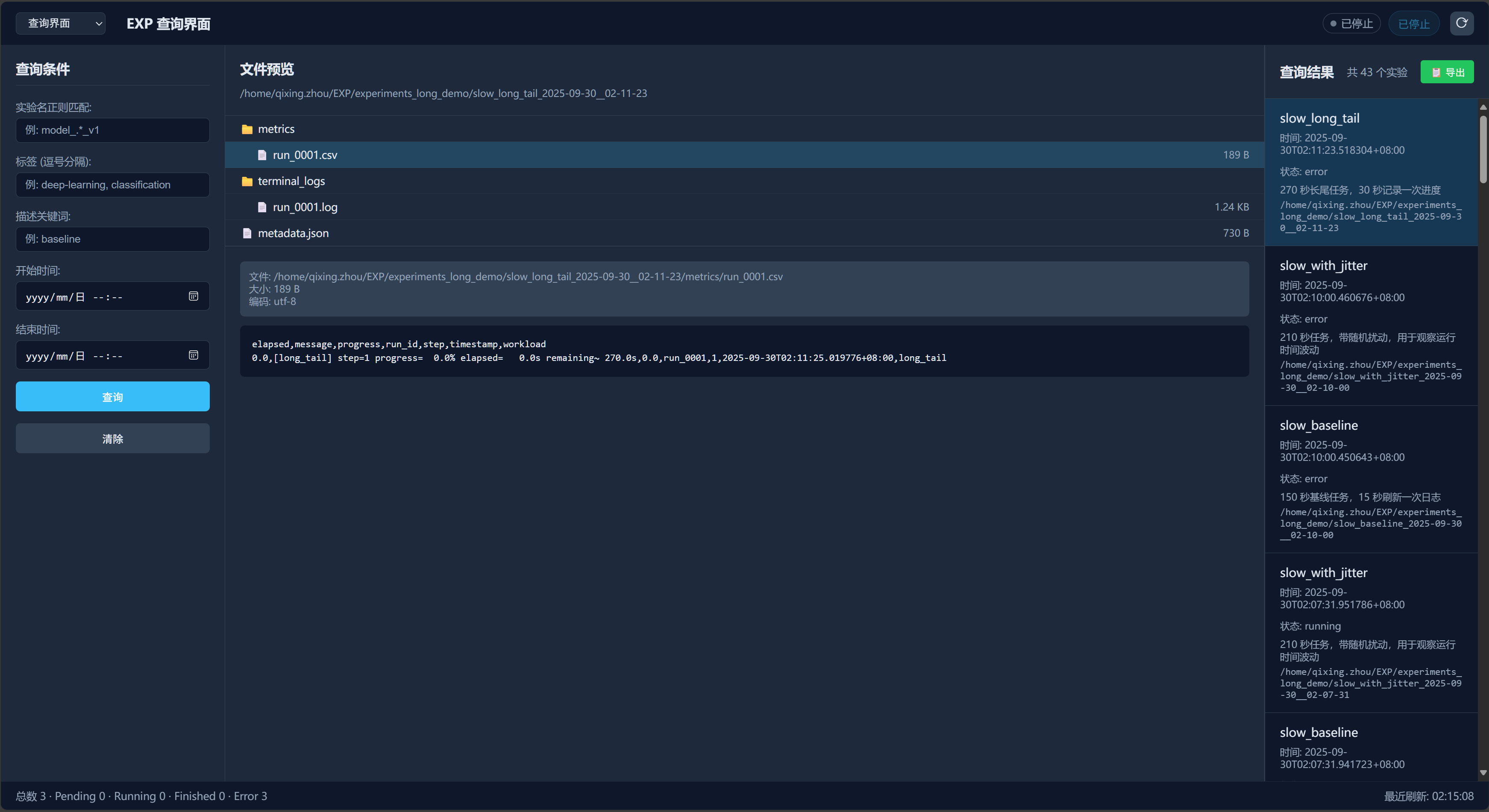
实验查询页面 - 实验查询与内容预览
只需完成两件事:
- 写包装脚本——用
Experiment包装你的训练命令,EXP 会负责目录、日志和状态。 - 写指标——在训练脚本中调用
load_experiment(),然后即可使用 EXP 提供的 api。
搞定这两步,就可以单点运行,也能批量调度。
pip install -e . 或者 pip install xpriment1. 创建一个 toy example
# 创建一个 toy 训练脚本 train.py
import time
from experiment_manager.core import load_experiment
exp = load_experiment()
for i in range(3):
exp.upd_row(step=i, loss=1.0/(i+1))
exp.save_row()
print(f"Step {i}, Loss: {1.0/(i+1):.3f}")
time.sleep(1)
# 创建包装脚本 run_exp.py
from pathlib import Path
from experiment_manager.core import Experiment
exp = Experiment(
name="test",
command="python train.py",
base_dir=Path("./results"),
cwd=Path(".")
)
exp.run(background=False) # True 时后台运行2. 运行并查看结果
python run_exp.py输出会在 <base_dir>/<name>_<timestamp>/
- 写一个最小配置
# config.toml
[scheduler]
base_experiment_dir = "./results"
max_concurrent_experiments = 2
[[experiments]]
name = "exp1"
command = "python train.py"
[[experiments]]
name = "exp2"
command = "python train.py"- 启动调度器并打开 UI
EXP run config.toml # 执行配置中所有实验
EXP see ./results # 可视化监控界面| API | 说明 |
|---|---|
Experiment(...) |
核心入口。常用参数:name(实验名)、command(实际训练命令)、base_dir(输出根目录)、cwd、tags、gpu_ids、description。若需要飞书同步,使用 lark_config 传入凭据或 URL,实例会在创建时生成工作目录并写入 metadata.json。 |
load_experiment() |
训练脚本内获取当前运行的 Experiment 实例。该函数依赖调度器或包装脚本注入的目录信息;如果直接裸跑脚本,会抛出说明性异常,提示未在 EXP 环境下启动。 |
exp.run(background=False, extra_env=None) |
启动训练命令并记录日志。background=True 时异步执行且自动创建输出线程;extra_env 可传字典为子进程增删环境变量。方法会维护运行状态并把 PID、日志路径等写入 metadata.json。 |
exp.upd_row(**metrics) |
累积一行指标数据到缓冲区(字典),常用于每个 step/epoch 结束后调用。支持任意键值对,默认将值转为字符串或数值,下一次 save_row() 会将本次更新写入 CSV。 |
exp.save_row(lark=False, lark_config=None) |
将缓冲区写入 <work_dir>/metrics/*.csv,必要时扩展字段并回填旧数据。lark=True 时会尝试同步飞书:默认使用实例创建时的 lark_config,也可以通过参数传入临时覆盖并在成功后持久化。 |
| 参数 | 类型 | 说明 | 示例 |
|---|---|---|---|
name |
str |
实验名称,最终目录名为 name_timestamp。 |
"cnn_small" |
command |
str |
实际执行的训练指令,会在 run() 时通过 shell 启动。 |
"python train.py --epochs 20" |
base_dir |
PathLike |
实验输出根目录,必须存在或可创建。 | Path("./experiments") |
tags |
List[str] |
可选标签,写入 metadata.json 方便筛选。默认 []。 |
["cnn", "baseline"] |
gpu_ids |
List[int] |
指定 GPU 序号,会自动设置 CUDA_VISIBLE_DEVICES。 |
[0, 1] |
cwd |
PathLike |
运行子进程时的工作目录,未提供则使用新建的实验目录。 | Path("./training") |
resume |
str |
继续已有实验,值为原目录时间戳(如 2025-09-30__11-02-13)。 |
"2025-09-30__11-02-13" |
description |
str |
备注信息,会写入 metadata.json 并在 UI 中展示。 |
"Sweep with cosine LR" |
lark_config |
Dict[str,str] | str |
飞书配置,支持直接传 URL (str) 或包含 app_id、app_secret、app_token、table_id 等键的字典。解析后会持久化,用于后续同步。 |
{"app_id": "cli_xxx", "app_secret": "xxx", "url": "https://example.feishu.cn/base/app123?table=tbl123"} |
无入参。从训练脚本中返回当前 Experiment 实例,若脚本未通过 EXP 启动则抛出异常。
| 参数 | 类型 | 说明 | 示例 |
|---|---|---|---|
background |
bool |
True 为后台执行并开启日志收集线程;False 时阻塞等待命令结束。默认 True。 |
background=False |
extra_env |
Dict[str, str] |
额外注入/覆盖的环境变量;值为 None 的键会被删除。 |
{"WANDB_MODE": "offline"} |
可变关键字参数:任意指标键值对,合并到内部缓冲区,直到下一次 save_row 时才写回。常见示例:
exp.upd_row(epoch=i, train_loss=loss, lr=scheduler.get_last_lr()[0])| 参数 | 类型 | 说明 | 示例 |
|---|---|---|---|
lark |
bool |
是否触发飞书同步。默认 False。 |
lark=True |
lark_config |
Dict[str,str] | str |
本次写入的飞书覆盖配置。若提供,将与实例已有配置合并(覆盖优先),并在成功后写入 metadata.json。 |
{"view_id": "vewABCDEFG"} |
- 在创建
Experiment(...)时直接通过lark_config提供飞书凭据,可传字典或 URL 字符串。 - 建议在字典中显式包含
app_id、app_secret、app_token、table_id(视图可选view_id)。若传入 URL,框架会自动解析app_token/table_id/view_id。 - 实例在首次同步成功后会将最终配置写入
metadata.json,resume或后续save_row(lark=True)会复用这份配置。
- 在
[scheduler]段落设置共享凭据,例如lark_config = { app_id = "cli_xxx", app_secret = "xxx" },避免每个实验重复填写。 - 每个
[[experiments]]可通过lark_url或lark_config覆盖/补充表格信息,字段会覆盖调度器级别的同名项。 - 若某实验需要独立账号,只需在该实验的
lark_config中补齐完整凭据即可。
- 调度模式下:
[scheduler].lark_config<[[experiments]].lark_config/lark_url。 - 单点实验:构造函数的
lark_config与实例已有配置(如resume读取的metadata.json)合并,新传入值优先。 exp.save_row(lark=True, lark_config=...)会在实例默认配置之上再次叠加本次调用的覆盖值。
This repository is licensed under the Apache-2.0 License.